Home Europakarte Weltkarte Arbeiten Impressum Sitemap
4.2.2. Wissen über die Komplexität und die Relevanz von RegelnSelbst unter der Bedingung, daß das nötige Wissen für die Beantwortung einer Frage sich explizit und seperat im wissensbasierten System befindet und durch das Benutzermodell die gewünschte Form der Erklärung bekannt ist, werden die Erklärungen noch nicht befriedigend sein. Einer der größten Nachteile von augenblicklichen Erklärungen ist, daß sie sehr lang sind und viele unwichtige Informationen wie beispielsweise Housekeeping und schon bekannte Informationen enthalten. Aufgrund dieser Tatsache sind die Erklärungen häufig schwer verständlich. Eine Erklärung erfordert nicht immer eine Beschreibung aller Details der kausalen Zusammenhänge. Abhängig vom Wissensstand des Benutzers, dem Kontext und der Dialoghistorie ist eine mehr oder weniger ausführliche Erklärung notwendig.311 Eine Erklärung muß so detailiert sein, daß sie einen Kontakt zu dem Wissen des Benutzers herstellt,312 aber nur soviel bekanntes Wissen enthält, wie zum Verständnis der Zusammenhänge notwendig ist. Das Problem besteht darin, daß dem System das Wissen fehlt, um zwischen den für die Erklärungen geeigneten und ungeeigneten Informationen zu unterscheiden. Ohne dieses Wissen können überflüssige oder unverständliche Informationen nicht aus den Erklärungen herausgefiltert werden. Wenn das wissensbasierte System Wissen über die Komplexität und Relevanz der gezogenen Schlußfolgerungen hat, dann könnten Erklärungen wie folgt generiert werden:
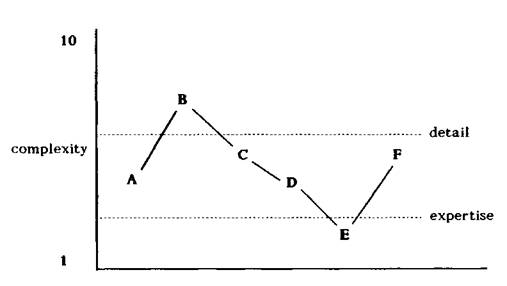
Abb. 16: Berücksichtigung der Komplexität bei der Erstellung von Erklärungen313
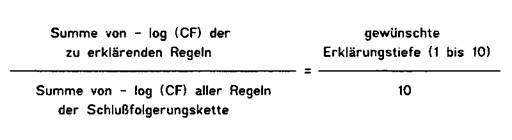
Diese beiden benutzerspezifischen Variablen begrenzen die Komplexität der Erklärungen nach oben und nach unten. Schlußfolgerungen, deren Komplexität über dem gewünschten Detaillierungsniveau315 liegen, werden nicht mit in die Erklärung aufgenommen.316 Dasselbe gilt für Schlußfolgerungen, die unter dem Expertiseniveau liegen, da in diesem Fall angenommen wird, daß der Benutzer dieses Wissen bereits besitzt. Mit Hilfe eines Benutzermodells kann selbstverständlich eine differenziertere Berücksichtigung des Vorwissens des Benutzers erfolgen.317 In diesem Kapitel wird dennoch diese Technik vorgestellt, da nicht immer ein derart differenziertes Benutzermodell zur Verfügung steht. In dem obigen Beispiel erhält der Benutzer nur die Ableitungskette A -> C -> D als Erklärung der Aussage F angezeigt. Die Schlußfolgerung B wurde als zu komplex und die Schlußfolgerung E als schon bekannt eingestuft. Es stellt sich nun die Frage, wie das wissensbasierte System die Relevanz und Komplexität einer Regel erkennen kann. Dieses Problem ergibt sich dadurch, daß kein gutes Maß für die Anzahl der Informationen in einer Regel existiert.318 Die einfachste Form, dieses Problem zu lösen, besteht darin, jeder Regel319 einen numerischen Relevanzwert und einen Komplexitätswert zuzuordnen.320 Diese Methode ist nicht unproblematisch, da die Relevanz von ein und derselben Regel für unterschiedliche Erklärungen verschieden sein kann. Darüberhinaus wird der Kontext bei der Einschätzung der Relevanz nicht berücksichtigt. Ein anderen Ansatz wird bei TEIRESIAS verfolgt. Dort werden die Sicherheitsfaktoren der Regeln als Maß für den Informationsgehalt verwendet.321 Es wird angenommen, daß eine Regel mit einem hohen Sicherheitsfaktor [certainty factor oder CF] 322 weniger Informationen enthält als eine Regel mit einem niedrigen, da derartige Regeln eher als Definitionen betrachtet werden können.323 DAVIS benutzt den Ausdruck -log (certainty factor) als ein Maß für den Informationsgehalt einer Regel.324 Wie aus Abb. 17 ersichtlich ist, erklärt das System so viele Regeln, bis die Summe von deren Sicherheitsfaktoren eine Größe erreicht, die beide Seiten der Formel ausgleicht.
Die Anzahl an Regeln, die als Erklärung ausgegeben werden, hängt von den beiden Faktoren, der gewünschten Erklärungsstufe und den Sicherheitsfaktoren, ab. Wenn der Benutzer eine hohe Erklärungsstufe wählt, dann umfaßt die Erklärung mehr Regeln als bei einer niedrigeren. Die Erklärung wird auch dann umfangreicher, wenn viele Regeln mit hohen Sicherheitsfaktoren in der Erklärung enthalten sind. Aufgrund des Ausdruckes -log (certainty factor) werden in diesem Fall mehr Regeln dargestellt.325 Das Problem bei dieser Technik besteht darin, daß die Sicherheitsfaktoren nicht immer einen Rückschluß auf die Relevanz einer Regel für Erklärungen erlauben.326 Neben der Tatsache, daß es keine formale Rechtfertigung dafür gibt, daß -log (certainty factor) ein gutes Maß für den Informationsgehalt ist, sollte ein derartiges Maß abhängig vom Wissen des Benutzers sein.327 Der Vorteil dieser Technik liegt darin, daß keine Ergänzungen in der Wissensbasis vorgenommen werden müssen. Bei dem DIGITALIS ADVISOR und BLAH wird die Detailliertheit an der Tiefe des Schlußfolgerungsbaums gemessen. Der Zusammenhang zwischen Tiefe und Detailliertheit ist ein Ergebnis der Hierarchie in der Wissensbasis,328
311 Vgl. SWARTOUT, W.R.; SMOLIAR, S.W.: On Making Expert Systems more Like Experts, a.a.O., S. 205. 312 Vgl. CLANCEY, W.J.: The Epistemology of a Rule-Based Expert System, a.a.O., S. 226 313 In Anlehnung an WALLIS, J.W.; SHORTLIFFE, E.H.: Explanatory Power for Medical Expert Systems, a.a.O., S. 132. 314 Diese Information kann von dem Benutzermodell oder direkt von dem Benutzer gegeben werden, indem er zusätzlich zur Frage einen Detaillierungsparameter angibt 'WHY 7'. Vgl. WALLIS, J.W.; SHORTLIFFE, E.H.: Explanatory Power for Medical Expert Systems, a.a.O., S. 132. 315 Der Defaultwert liegt bei 2 + Wissensstand. Dieser Wert kann durch Nachfragen des Benutzers oder durch das Benutzermodell erhöht werden. 316 Ausnahmen werden bei Schlußfolgerungen mit einer sehr hohen Relevanz gemacht, vergl. Vgl. WALLIS, J.W.; SHORTLIFFE, E.H.: "Explanatory Power for Medical Expert Systems, a.a.O., S. 133. 317 Siehe Kap. 4.3.1. 318 Vgl. DAVIS, R.; BUCHANAN, B.; SHORTLIFFE, E.: Production Rules as a Representation for a Knowledge-Based Consultation Program, a.a.O., S. 26. 319 Diese Technik ist auch bei anderen Wissensrepräsentationsformen anwendbar. 320 Vgl. WALLIS, J.W.; SHORTLIFFE, E.H.: Explanatory Power for Medical Expert Systems, a.a.O., 130. 321 Vgl. WEINER, J.L.: BLAH, A System Which Explains its Reasoning, a.a.O., S. 26. 322 In der Medizin können viele Aussagen nicht mit völliger Sicherheit getroffen werden. In diesem Fall verwendet MYCIN Sicherheitsfaktoren [certainty factors], um das unsichere Wissen zu repräsentieren und zu verarbeiten. Bei diesen Sicherheitsfaktoren handelt es sich um nummerische Werte zwischen -1 (völlig falsch) und *■! (100% richtig). Ein Sicherheitsfaktor wird errechnet aus der Summe von zwei Werten. Diese beiden Werte repräsentieren die subjektive Einschätzung des Vertrauens und des Mißtrauens in eine Hypothese. Vgl. BECKER, B.: Defizite von Expertensystemen, über Möglichkeiten und Grenzen intelligenter Computersysteme, in: BECKER, B.; WINKELMANN, G. (HRSG.): Computer-Intelligenz contra menschliche Intelligenz, DAG-Hausdruck 2/85 - 35-49893-59, 1985, 3. 22f. 323 Vgl. SWARTOUT, W.R.: A Digitalis Therapy Advisor with Explanations, a.a.O., S. 820. 324 Vgl. DAVIS, R.; BUCHANAN, B.; SHORTLIFFE, E.: Production Rules as a Representation for a Knowledge-Based Consultation Program, a.a.O., S. 26. 325 Der Logarithmus ist die Umkehrung des Potenzierens. log (100) ist 3 da 103 = 100. Bei dem log von Zahlen zwischen 0 und 1, wie sie bei den Sicherheitsfaktoren auftreten, ergeben sich negative Werte, die um so höher sind je kleiner die Zahl ist. |